Las pruebas de conocimiento cero (ZKPs) representan un avance revolucionario en integridad computacional, permitiendo que una parte demuestre la correcta ejecución de un cómputo sin revelar las entradas privadas subyacentes. Históricamente, el overhead de ingeniería requerido para construir estas pruebas ha sido inmenso. Los desarrolladores se veían obligados a escribir la lógica general de sus aplicaciones en lenguajes tradicionales mientras implementaban la lógica de validación criptográfica en lenguajes de circuitos altamente especializados y de bajo nivel. Esta bifurcación inevitablemente conduce a esfuerzo duplicado, desajustes lógicos y vulnerabilidades de seguridad severas.
El lenguaje de programación Achronyme fue diseñado para resolver este desajuste de impedancia fundamental. Mediante la utilización de un entorno de ejecución dual, Achronyme permite a los desarrolladores escribir programas de conocimiento cero usando una sintaxis única y unificada. El compilador toma un Árbol de Sintaxis Abstracta (AST) unificado y lo enruta hacia dos modelos de ejecución completamente diferentes: una Máquina Virtual (VM) estándar y de propósito general para ejecución dinámica, y un compilador de restricciones aritméticas altamente especializado para la generación de pruebas de conocimiento cero.
Este informe de investigación proporciona un análisis técnico exhaustivo del pipeline de compilación de conocimiento cero de Achronyme. Enfocándose específicamente en la ruta ach circuit, el análisis deconstruye cómo las construcciones programáticas de alto nivel se transforman sistemáticamente en representaciones intermedias, se optimizan rigurosamente para aritmética de campos finitos, y finalmente se traducen en Sistemas de Restricciones de Rango 1 (R1CS) o aritmetizaciones Plonkish. Examinando la lógica del código fuente —desde los puntos de entrada hasta la implementación de elementos de campo BN254 a bajo nivel— este informe tiende un puente conceptual entre el diseño tradicional de compiladores y las estrictas realidades matemáticas de los circuitos criptográficos.
Los Dos Caminos: Divergencia Arquitectónica desde un Único AST
La arquitectura del compilador de Achronyme se define por una bifurcación estricta que ocurre inmediatamente después de la fase de análisis sintáctico. El proceso comienza en el módulo achronyme-parser, donde un lexer Pratt escrito a mano y un parser de descenso recursivo analizan el código fuente .ach para producir un Árbol de Sintaxis Abstracta (AST) estándar. En esta coyuntura, la lógica de orquestación determina la trayectoria de compilación basándose en los argumentos de la interfaz de línea de comandos (CLI) invocados: ach run o ach circuit.
El AST diverge tras el análisis sintáctico en dos paradigmas computacionales vastamente diferentes. La ruta primaria, invocada mediante ach run, dirige el AST hacia un compilador de bytecode que alimenta una máquina virtual personalizada al estilo von Neumann. Esta ruta de la VM maneja la ejecución dinámica y proporciona un entorno rico en funcionalidades, completo con recolección de basura (GC), asignación dinámica de memoria, soporte para closures complejos, llamadas a funciones recursivas y operaciones nativas de entrada/salida (E/S). Opera secuencialmente, ejecutando instrucciones y mutando estado a lo largo del tiempo, reflejando el comportamiento de intérpretes estándar como la Java Virtual Machine o V8.
Por el contrario, la ruta secundaria, invocada mediante ach circuit, impone el desenrollado estático y la traducción a restricciones polinomiales sobre campos finitos. La ruta de compilación de circuitos elimina la ilusión del tiempo y la memoria dinámica, forzando al programa hacia una representación matemática estática. En criptografía, una prueba de conocimiento cero no interactiva (como un zk-SNARK) requiere que el demostrador acredite conocimiento de un “testigo” (un vector de valores) que satisface un sistema altamente específico y de tamaño fijo de ecuaciones polinomiales. Dado que los circuitos aritméticos son grafos estáticos de relaciones matemáticas, no poseen contador de programa, ni pila, ni memoria mutable.
En consecuencia, la ruta de compilación ach circuit impone restricciones rigurosas sobre el AST fuente que se aplican en tiempo de compilación:
- Eliminación del Flujo de Control Dinámico: Aunque el AST puede contener condicionales if/else, estos no pueden ejecutarse dinámicamente. Los circuitos de hardware no pueden “saltar” instrucciones basándose en datos de tiempo de ejecución. El circuito debe contener físicamente la lógica de evaluación tanto de la rama if como de la rama else, multiplexando el resultado final basándose en la condición booleana evaluada como una fórmula matemática.
- Prohibición de Bucles No Acotados: Construcciones como bucles while, o bucles for donde las condiciones de acotamiento se determinan en tiempo de ejecución, son explícitamente rechazadas. Además, interrupciones del flujo de control como break y continue no pueden utilizarse en modo circuito. Para traducir un bucle en una ecuación estática, el número exacto de iteraciones debe conocerse en tiempo de compilación para que el cuerpo del bucle pueda desenrollarse estáticamente en una secuencia plana y lineal de operaciones.
- Inmutabilidad Estricta y Ausencia de E/S: No existe el concepto de solicitudes de red dinámicas, lecturas de disco o mutación de memoria durante la evaluación del circuito. El concepto de mutación de estado es una abstracción que el compilador debe eliminar. Esto se logra mediante la generación de una Representación Intermedia (IR) en forma de Asignación Única Estática (SSA), donde las variables son matemáticamente inmutables una vez asignadas.
Estas restricciones no son decisiones de diseño arbitrarias; son prerrequisitos matemáticos absolutos dictados por el proceso de aritmetización de protocolos como Groth16 o PlonK. Un sistema de restricciones polinomiales no puede presentar un número desconocido de términos (que un bucle dinámico generaría) y no puede omitir condicionalmente variables sin destruir sus propiedades algebraicas. El mandato fundamental del compilador es aplanar la estructura multidimensional y temporal de un programa de software en una declaración matemática unidimensional y estática.
Del AST a SSA IR: La Fase de Transformación
La transformación del AST de alto nivel a la Representación Intermedia (IR) es orquestada dentro de los módulos de tipos de IR, transformación y expresiones. Achronyme utiliza una forma de Asignación Única Estática (SSA). En SSA estándar, cada variable se asigna exactamente una vez, y cada variable se define antes de ser utilizada. Esta arquitectura refleja perfectamente la naturaleza matemática de las restricciones de conocimiento cero: una restricción de igualdad no es una asignación imperativa que pueda actualizarse en un ciclo de reloj posterior; es una declaración permanente e inmutable de verdad para esa configuración específica del testigo.
El Rechazo Arquitectónico de los Phi-Nodes
La desviación arquitectónica más notable en la implementación SSA de Achronyme, particularmente cuando se compara con compiladores industriales tradicionales como LLVM o GCC, es la ausencia completa e intencional de -nodes (phi-nodes).
En la forma SSA tradicional, un -node es una instrucción especial utilizada para fusionar variables que han sido asignadas en caminos de flujo de control divergentes y mutuamente excluyentes. Si un programa contiene un bloque if/else donde una variable x se asigna el valor a en la rama verdadera y b en la rama falsa, el bloque básico subsiguiente en el Grafo de Flujo de Control (CFG) comenzará con una declaración como x_3 = phi(x_1, x_2). La función selecciona dinámicamente el valor de x_1 o x_2 dependiendo de qué bloque básico se ejecutó inmediatamente antes de alcanzar el punto de fusión.
En un circuito de conocimiento cero, el flujo de control dinámico no existe. El circuito es una fórmula matemática estática evaluada simultáneamente. El demostrador proporciona un testigo completo, y el verificador comprueba las relaciones aritméticas entre todos los valores en ese testigo. Una ecuación polinomial no puede ignorar selectivamente términos basándose en la evaluación de otros términos sin destruir su solidez algebraica.
Por lo tanto, la fase de transformación de Achronyme evita explícitamente los -nodes y sus complejidades asociadas, como el cálculo de fronteras de dominancia o árboles de dominadores (por ejemplo, el algoritmo de Lengauer-Tarjan). En su lugar, aplana el flujo de control utilizando una construcción de multiplexor matemático, representada internamente como una instrucción Mux. Cuando el compilador encuentra una expresión if/else, evalúa recursivamente tanto el bloque AST del if como el bloque AST del else, independientemente de la condición. Luego emite una instrucción Mux que selecciona matemáticamente el valor correcto usando interpolación algebraica:
Dado que la variable está rigurosamente restringida a ser un valor booleano ( o ), esta ecuación selecciona limpiamente cuando la condición es verdadera () y cuando la condición es falsa ().
Considérese la compilación concreta de una asignación condicional: let r = if condition { a } else { b };.
El compilador de Achronyme transforma este nodo AST de alto nivel directamente en la siguiente secuencia plana de SSA IR:
| ID de Instrucción IR | Operación | Argumentos | Equivalente Matemático |
|---|---|---|---|
| v0 | Load | condition | Cargar booleano |
| v1 | Load | a | Cargar valor |
| v2 | Load | b | Cargar valor |
| v3 | Sub | 1, v0 | Calcular |
| v4 | Mul | v0, v1 | Calcular |
| v5 | Mul | v3, v2 | Calcular |
| v6 | Add | v4, v5 | Calcular |
| r | Store | v6 | Asignar a la salida |
Esta decisión de diseño simplifica profundamente el análisis de flujo de datos aguas abajo. Dado que no existen bloques básicos distintos conectados por lógica de ramificación condicional, el Grafo de Flujo de Control es completamente lineal. El compilador no necesita resolver problemas de copia perdida ni problemas de intercambio asociados con la destrucción de -nodes durante la generación de código en el backend. El circuito completo representa un único bloque básico monolítico, mapeándose perfectamente a un sistema de restricciones.
Desenrollado Estático de Bucles e Inlining de Funciones
De manera similar, el manejo de bucles y llamadas a funciones, está dictado por la naturaleza estática de los backends criptográficos objetivo.
Un mecanismo de bucle tradicional depende de un salto hacia atrás en el puntero de instrucciones (por ejemplo, una instrucción JMP en ensamblador) hasta que una condición específica se evalúa como falsa. Dado que un circuito aritmético carece de puntero de instrucciones o del concepto de repetición temporal, todas las iteraciones de un bucle deben existir como restricciones matemáticas distintas y secuenciales. Cuando el compilador encuentra una construcción como for i in 0..3 { sum = sum + arr[i]; }, evalúa los límites estáticamente. Si los límites son dinámicos y no pueden resolverse en tiempo de compilación, el compilador se detiene y emite un error.
Si los límites son estáticamente conocidos, el compilador realiza un desenrollado de bucle obligatorio y exhaustivo. Duplica el AST del cuerpo del bucle para cada iteración, sustituyendo la variable de índice del bucle con el valor entero concreto para esa pasada específica.
La representación AST original:
for i in 0..3 { sum = sum + arr[i]; }
Se transforma en el SSA IR como si el desarrollador hubiera escrito explícitamente la lógica secuencial:
| Iteración del Bucle | Emisión Simulada de SSA IR |
|---|---|
| i = 0 | v_sum_1 = Add(v_sum_0, arr) |
| i = 1 | v_sum_2 = Add(v_sum_1, arr) |
| i = 2 | v_sum_3 = Add(v_sum_2, arr) |
Las llamadas a funciones se tratan con una filosofía idéntica. No existe pila de llamadas, ni puntero de frame, ni dispatch dinámico en un circuito aritmético. Cada llamada a función se inserta (inline) de manera completa e incondicional. El compilador mapea los argumentos a los parámetros de la función, procesa el AST de la función en una secuencia de instrucciones SSA, y empalma esas instrucciones directamente en la secuencia monolítica de IR. Si bien este enfoque garantiza que el circuito resultante represente las restricciones matemáticas exactas del programa, introduce una compensación: el tamaño de la salida de compilación (y consecuentemente, el tiempo de generación de pruebas) crece linealmente con el número de iteraciones de bucle e invocaciones de funciones.
Pasadas de Optimización: Minimizando la Huella de Restricciones
En la compilación tradicional, las pasadas de optimización apuntan principalmente a ciclos de CPU en tiempo de ejecución, localidad de caché y huella de memoria. En el paradigma de conocimiento cero, el tamaño del sistema de restricciones resultante dicta el rendimiento del demostrador criptográfico. El tiempo de generación de pruebas es consistentemente el mayor cuello de botella en sistemas ZK, escalando cuasi-linealmente con el número de restricciones (por ejemplo, para operaciones que involucran Transformadas Rápidas de Fourier en algoritmos como Groth16). En consecuencia, la optimización del compilador no es meramente una herramienta para generar binarios más rápidos; es un requisito crítico e intransigente para hacer las pruebas criptográficas computacionalmente viables.
Achronyme implementa cuatro pasadas de optimización específicas sobre el SSA IR aplanado, definidas en el módulo de pasadas de optimización. Aunque sus nombres reflejan pasadas estándar de compilador, sus fundamentos y mecánicas subyacentes están adaptados de manera única a la aritmética de campos finitos y los paradigmas de seguridad ZK.
1. Plegado de Constantes: Erradicación de Restricciones
En un compilador estándar, el plegado de constantes evalúa expresiones deterministas en tiempo de compilación (por ejemplo, reemplazar 5 * 8 con 40) para ahorrar algunos ciclos de CPU en tiempo de ejecución. En Achronyme, el plegado de constantes elimina restricciones criptográficas por completo. Si el compilador encuentra let x = 5 * 8;, evalúa esto nativamente como 40 y reemplaza todos los usos de x con el literal de elemento de campo 40. Dado que estos valores son completamente deterministas, no necesitan asignarse a wires de testigo privado en el circuito. En su lugar, las constantes se incrustan directamente en las matrices de restricciones como coeficientes fijos y públicos. Esta optimización reduce la dimensión del vector testigo y elimina la puerta de multiplicación que habría sido necesaria para demostrar matemáticamente que .
2. Eliminación de Código Muerto (DCE): Podando el Grafo
La Eliminación de Código Muerto remueve instrucciones no utilizadas del IR. Dado que el IR de circuito de Achronyme es perfectamente lineal y carece de ramas o -nodes, la DCE se implementa como un recorrido de grafo de flujo de datos en orden inverso altamente eficiente. Cualquier variable SSA que nunca es leída por una instrucción subsiguiente —y no representa una salida pública requerida ni una aserción obligatoria— se poda del IR. Esta pasada es vital para prevenir la generación de restricciones “huérfanas” que sobrecargan al demostrador con el cómputo y compromiso de valores que no contribuyen a la verdad final de la declaración que se está demostrando.
3. Propagación Booleana: Optimización Algebraica Especializada
La propagación booleana es una optimización altamente especializada, única para la compilación algebraica y basada en restricciones. En circuitos ZK, todas las variables son fundamentalmente elementos de campo, lo que significa que pueden tomar cualquier valor entero hasta un primo masivo . Para imponer que una variable se comporte estrictamente como un booleano binario (restringido a o ), el circuito debe inyectar una restricción cuadrática: .
Esta ecuación polinomial solo se cumple si o . Sin embargo, estas restricciones booleanas son matemáticamente costosas. Si un desarrollador usa un valor booleano en múltiples lugares, un compilador ingenuo podría emitir la restricción repetidamente. Además, si es la salida de una comparación lógica (que inherentemente produce o basándose en su lógica interna), la naturaleza booleana de la variable ya está garantizada por la lógica precedente.
La pasada de Propagación Booleana de Achronyme utiliza técnicas de propagación de cotas —similares a las usadas en Programación Lineal Entera (ILP) y resolvedores SAT— para rastrear el estado de “booleano demostrado” de cada variable en el grafo SSA. El compilador mantiene un conjunto especializado de IDs SSA que han sido matemáticamente restringidos a los límites . Cuando una instrucción requiere una entrada booleana (como la variable de condición en un multiplexor Mux), el compilador consulta este conjunto. Si la variable ya está clasificada como un booleano demostrado, el compilador omite de forma segura la generación de la restricción de aplicación redundante, ahorrando una puerta de multiplicación por cada omisión.
4. Análisis de Contaminación: Asegurando la Integridad del Circuito
De todas las pasadas de optimización, el Análisis de Contaminación es la más crucial para la seguridad criptográfica fundamental de la aplicación. En la ingeniería de software tradicional, una entrada no utilizada o una variable sub-restringida podría resultar en un error lógico menor o desperdicio de memoria. En un circuito de conocimiento cero, una variable sub-restringida representa una vulnerabilidad catastrófica y sistémica.
Una prueba de conocimiento cero verifica únicamente las restricciones matemáticas explícitamente codificadas dentro del circuito. Si un desarrollador declara una variable de testigo privado representando una secret_key, pero omite incluir una aserción que verifique una firma criptográfica contra esa clave, la variable queda efectivamente sin restricciones. Un demostrador malicioso podría suministrar cualquier valor arbitrario para secret_key, generar una prueba matemática perfectamente válida, y eludir por completo la lógica de autenticación prevista.
Achronyme aprovecha el análisis de contaminación estático —tomando conceptos de herramientas de análisis de flujo de información como FlowDroid— para detectar estas vulnerabilidades en tiempo de compilación. El compilador trata todas las entradas de testigo privado como fuentes “contaminadas”. Traza el grafo de flujo de datos hacia adelante para asegurar que cada variable contaminada eventualmente fluya hacia un sumidero verificado: una aserción obligatoria, una salida pública, o una primitiva criptográfica restringida (como una función hash). Si una variable de testigo alcanza el final del grafo de flujo de datos sin afectar ninguna salida restringida, el compilador emite una advertencia severa indicando que el circuito está sub-restringido. Esta verificación de seguridad proactiva y en tiempo de compilación previene vulnerabilidades críticas antes de que una sola prueba sea generada.
IR a R1CS: El Sistema de Restricciones de Rango 1
Después de que las pasadas de optimización reducen el SSA IR a su forma mínima necesaria, el compilador debe traducir estas instrucciones abstractas al formato matemático nativo del backend criptográfico elegido. Para el demostrador Groth16, este formato objetivo es el Sistema de Restricciones de Rango 1 (R1CS), gestionado en los módulos de backend y restricciones R1CS.
R1CS es un esquema de aritmetización donde un cómputo completo se representa globalmente como un conjunto de tres matrices , y , junto con un único vector testigo . El sistema se satisface matemáticamente si, y solo si, la siguiente ecuación se cumple:
Aquí, denota el producto de Hadamard, representando la multiplicación elemento a elemento de los vectores resultantes. Esta estructura rígida implica que cada fila en el sistema matricial representa exactamente una multiplicación de dos combinaciones lineales. La elegancia —y la limitación computacional fundamental— de R1CS es que soporta nativamente adición ilimitada y multiplicación escalar de forma gratuita, pero limita estrictamente el circuito a exactamente una multiplicación de variables distintas por fila de restricción.
El Invariante Estricto del Layout de Wires
Para facilitar este álgebra matricial, el vector testigo (frecuentemente referido como el layout de wires) debe adherirse a un invariante de ordenamiento altamente específico. En Achronyme, el layout de wires está estrictamente ordenado como:
[ONE, ...public_inputs, ...private_witnesses]
¿Por qué ONE? La constante siempre debe ser el primer elemento (índice 0) del vector testigo. Dado que la lógica R1CS depende puramente de combinaciones lineales de variables, no existe un mecanismo inherente para agregar una constante desnuda a una variable sin multiplicarla por un valor ya conocido presente en el vector. Si una operación requiere sumar la constante 5 a una variable , la combinación lineal debe expresarse matemáticamente como . Al fijar permanentemente el índice 0 del vector testigo al elemento de campo constante , las constantes pueden integrarse sin problemas e infinitamente en las matrices y .
¿Por qué Público antes que Privado? Las entradas públicas deben preceder a los datos de testigo privado debido a la mecánica operacional de los protocolos de verificación basados en emparejamientos. Durante la fase de verificación de la prueba, el verificador (que puede ser un contrato inteligente en una blockchain) debe construir un subconjunto de la ecuación polinomial usando únicamente los datos públicamente conocidos. Al agrupar todas las entradas públicas al inicio del vector, el protocolo criptográfico puede dividir limpiamente el vector en un segmento público (procesado económicamente por el verificador) y un segmento privado (procesado únicamente por el demostrador durante la generación de pruebas).
Trazando un Circuito Aritmético Concreto
Considérese la compilación de una declaración simple de circuito aritmético que representa la ecuación central :
pub x; witness y; assert_eq(x * y + 1, 42);
El SSA IR optimizado proporciona una única instrucción para aplicar esta relación. El compilador debe mapear esto al formato . La igualdad matemática es , que se reorganiza algebraicamente a una restricción de multiplicación pura:
El vector de wires es inicializado por el compilador como [ ONE, x, y ] (donde la constante ONE está en el índice 0, es la entrada pública en el índice 1, e es el testigo privado en el índice 2).
Para codificar la restricción , el compilador de Achronyme genera una única fila en las matrices de restricciones:
- El vector debe extraer : [ 0, 1, 0 ]
- El vector debe extraer : [ 0, 0, 1 ]
- El vector debe extraer la constante : [ 41, 0, 0 ]
Al tomar el producto punto con el vector de wires :
El producto de Hadamard asegura . Esto aplica perfectamente la lógica usando exactamente una restricción R1CS.
Gadgets No Nativos y Descomposición en Bits
Un desafío de diseño crítico surge cuando una expresión no se ajusta naturalmente a la forma cuadrática . R1CS no posee instrucciones de CPU nativas como división (/), módulo (%), o comparaciones a nivel de bits (>, <). El compilador debe reemplazar estas operaciones de alto nivel con “gadgets” —sub-circuitos complejos de restricciones que aplican algebraicamente exactamente la misma lógica.
Por ejemplo, una operación de división no puede evaluarse directamente porque los campos finitos no soportan división de punto flotante ni división entera estándar. El compilador reescribe esto como una restricción de multiplicación: . El demostrador es responsable de calcular el inverso modular de nativamente durante la ejecución para encontrar , pero el circuito solo demuestra que la multiplicación inversa se cumple.
Las comparaciones, como , son increíblemente costosas en R1CS. Dado que los elementos de campo existen en un espacio de aritmética modular sin ordenamiento intrínseco más allá de su representación en bits, comparar dos números requiere una descomposición completa en bits. El compilador debe extraer la representación binaria de las variables, restringir cada bit individual a ser booleano (), y luego realizar una sustracción bit a bit para verificar el desbordamiento negativo matemático. Una sola comparación menor-que en el campo BN254 genera aproximadamente 254 restricciones distintas. Esta disparidad extrema en costo —donde una multiplicación cuesta 1 restricción y una simple comparación cuesta 254— resalta precisamente por qué se requieren estrictamente estrategias de compilación especializadas para ZK.
IR a Plonkish: El Backend Alternativo
Aunque R1CS es elegante e ideal para generar pruebas mediante el protocolo Groth16, posee limitaciones notables respecto al uso de memoria, el requisito de configuraciones confiables específicas por circuito, y su incapacidad para manejar naturalmente lógica personalizada compleja. Achronyme mitiga estas limitaciones proporcionando una ruta de compilación secundaria y altamente optimizada hacia el esquema de aritmetización “Plonkish”, utilizado por el demostrador KZG-PlonK, gestionado en el módulo del backend Plonkish.
La aritmetización Plonkish representa restricciones no como matrices independientes y aisladas, sino como una matriz rectangular continua (o grilla) de valores, frecuentemente referida como traza de ejecución. En lugar de depender del formato , Plonkish se basa en una ecuación fundamental de gate personalizado, gobernada por una serie de “polinomios selectores”:
En esta arquitectura, y representan los valores físicos de wire (entrada izquierda, entrada derecha y salida), mientras que las variables () son constantes selectoras fijas definidas por el compilador para dictar el comportamiento del gate para esa fila específica.
Para realizar una adición estándar, el compilador simplemente desactiva el selector de multiplicación estableciendo , reduciendo la ecuación a . Para realizar una multiplicación, activa y ajusta apropiadamente los selectores de adición.
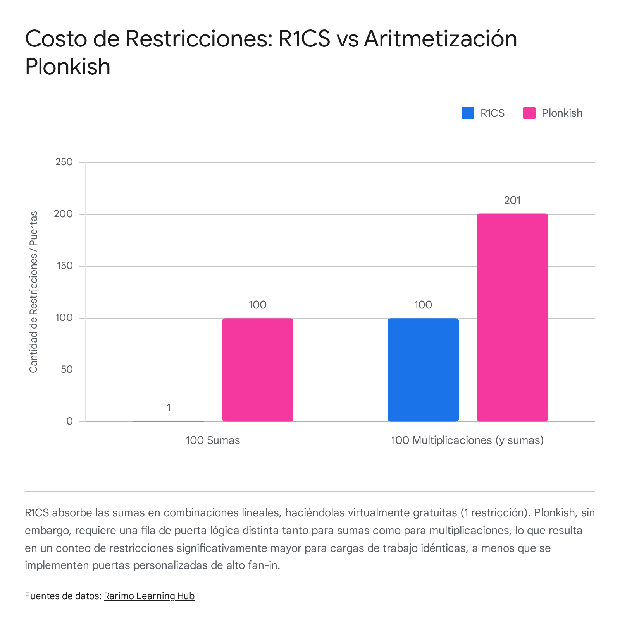
Divergencia Estructural y Características Avanzadas de Plonkish
La diferencia estructural entre los backends obliga al compilador de Achronyme a utilizar estrategias de layout drásticamente diferentes dependiendo de la aritmetización elegida.
En R1CS, un árbol de adición que comprende cientos de variables (por ejemplo, ) es absolutamente gratuito porque todos los términos pueden incorporarse en una única combinación lineal dentro de un solo vector matricial. En Plonkish, sin embargo, la ecuación estándar del gate acepta nativamente solo tres variables (). Por lo tanto, un árbol de adición grande debe descomponerse en múltiples gates secuenciales, consumiendo sustancialmente más filas e incrementando el tiempo de generación de pruebas para operaciones lineales.
Sin embargo, Plonkish compensa esta limitación con dos ventajas estructurales masivas: Restricciones de Copia y Argumentos de Lookup.
Dado que las variables en Plonkish se colocan en una grilla altamente estructurada, el compilador puede imponer igualdad matemática entre variables utilizadas en partes completamente diferentes del circuito mediante un argumento de permutación, comúnmente referido como restricciones de copia. Si una variable x se calcula en la fila 5 y se requiere nuevamente en la fila 500, el compilador no necesita re-verificar su linaje algebraico ni gastar restricciones moviéndola. Simplemente afirma que la celda en (fila 5, columna a) es matemáticamente idéntica a la celda en (fila 500, columna b). Esta capacidad de enrutamiento global reduce significativamente el overhead de rastrear estados de variables a través de rutas lógicas complejas.
Además, Plonkish permite al compilador de Achronyme utilizar Argumentos de Lookup (frecuentemente implementados como PLOOKUP). Para operaciones que son altamente ineficientes de computar algebraicamente —como XOR a nivel de bits, AND, o verificaciones de rango— el compilador puede pre-computar una tabla masiva y estática de todas las combinaciones válidas de entrada y salida. En lugar de descomponer variables en 254 restricciones binarias individuales para realizar una sola operación XOR, el backend Plonkish simplemente emite una restricción afirmando que la tupla existe en algún lugar dentro de la tabla de lookup pre-computada. Este mecanismo colapsa efectivamente miles de restricciones matemáticas complejas en una sola búsqueda de tabla eficiente, acelerando dramáticamente el procesamiento de primitivas criptográficas estándar y aritmética a nivel de bits.
Aritmética de Campo: La Base Matemática
Independientemente del objetivo de compilación seleccionado (R1CS o Plonkish), toda la aritmética dentro de Achronyme está estricta y universalmente definida sobre el campo escalar BN254. Este es un campo finito específico caracterizado por un orden primo (específicamente 21888242871839275222246405745257275088548364400416034343698204186575808495617).
La decisión de codificar BN254 de forma fija es completamente pragmática. BN254 está profundamente arraigado en el ecosistema blockchain debido a su soporte nativo mediante precompiles en la Máquina Virtual de Ethereum (EVM). Al apuntar a este campo específico, Achronyme asegura que los archivos .r1cs y .wtns generados puedan exportarse directamente a herramientas como snarkjs para generar contratos verificadores en Solidity, permitiendo que las pruebas se verifiquen nativamente on-chain. En consecuencia, cada variable, flag booleano, dirección de memoria e índice de arreglo en Achronyme se procesa fundamentalmente como un elemento de campo escalar de 254 bits.
Dado que el hardware anfitrión que ejecuta el compilador y el demostrador (usualmente una CPU x86 o ARM estándar) opera nativamente con registros de 64 bits, computar aritmética modular sobre un primo de 254 bits es computacionalmente exigente. Las operaciones estándar de módulo (división) se encuentran entre las instrucciones más costosas en un pipeline de CPU moderno. Para eludir esta limitación del hardware, el compilador de Achronyme implementa representación de Montgomery para todos los cálculos internos de elementos de campo.
La aritmética de Montgomery transforma las variables de su forma estándar a una forma escalada , donde es una potencia de 2 altamente optimizada (típicamente para alinearse perfectamente con los cuatro limbs de 64 bits usados para almacenar el entero de 254 bits).
La brillantez de la forma de Montgomery es evidente durante la multiplicación de campo. En lugar de ejecutar el cómputo estándar , que requiere una costosa división de multi-precisión para encontrar el residuo, el runtime computa la multiplicación de Montgomery:
Dado que es una potencia de 2, multiplicar por su inverso reduce efectivamente la división compleja a una serie de desplazamientos binarios y operaciones de enmascaramiento a nivel de bits, que están fuertemente aceleradas por hardware en procesadores modernos. Al mapear la aritmética de campo del AST directamente al espacio de Montgomery usando limbs de 4x64 bits, Achronyme logra la generación de pruebas nativa de alto rendimiento en proceso, necesaria para generar pruebas de conocimiento cero complejas rápidamente, evitando por completo la necesidad de depender de herramientas externas más lentas en JavaScript o Python.
Poseidon: Una Función Hash Nativa para ZK
La ingeniería de software tradicional depende en gran medida de hashes criptográficos estandarizados como SHA-256 o Keccak-256 para integridad de datos y compromisos. Sin embargo, intentar integrar estos algoritmos estándar en un circuito de conocimiento cero expone el desajuste fundamental entre las arquitecturas de CPU y las restricciones de campos finitos.
SHA-256 fue diseñado explícitamente para ser rápido en CPUs de hardware. Opera intensivamente sobre palabras de 32 bits usando operaciones rápidas a nivel de bits como AND, XOR y desplazamientos de bits (SHR). Como se estableció previamente, las operaciones a nivel de bits en sistemas de restricciones algebraicas requieren descomponer completamente las variables en bits individuales, costando cientos de restricciones por operación. Evaluar un solo hash SHA-256 en R1CS consume aproximadamente entre 25,000 y 30,000 restricciones. En un sistema donde el tiempo de generación de pruebas y el uso de memoria escalan directamente con la cantidad de restricciones, depender de SHA-256 hace que la verificación de datos a gran escala sea computacionalmente intratable.
Para resolver este severo cuello de botella, el sistema de restricciones de Achronyme integra nativamente el algoritmo de hash Poseidon, con los detalles de su implementación alojados en el módulo de restricciones Plonkish. Poseidon es una función hash algebraica “nativa para ZK”, diseñada desde cero para minimizar restricciones sobre campos primos como BN254.
En lugar de depender de manipulación a nivel de bits, Poseidon opera mediante rondas algebraicas completas y parciales utilizando la construcción de esponja Hades. Una ronda típica consiste en agregar constantes de ronda (una operación lineal gratuita en R1CS), multiplicar el estado por una matriz de Separabilidad Máxima de Distancia (MDS) (que requiere solo combinaciones lineales, también prácticamente gratuitas en R1CS), y pasar el estado a través de una S-box no lineal.
Crucialmente, la S-box en Poseidon no es una tabla compleja de búsqueda de bytes como las usadas en AES, sino más bien una exponenciación polinomial simple de bajo grado. Sobre el campo BN254, Poseidon usa específicamente , lo que significa que la S-box mapea el elemento de estado a .
Dado que puede calcularse algebraicamente mediante multiplicaciones sucesivas simples:
- Calcular
- Calcular
- Calcular
La operación no lineal completa de la S-box requiere solo 3 multiplicaciones de campo, y por tanto exactamente 3 restricciones R1CS. Esta profunda optimización matemática permite a Achronyme restringir un cómputo completo de hash Poseidon usando solo ~200 a 300 restricciones totales, haciéndolo aproximadamente 100 veces más eficiente que un circuito SHA-256 comparable. Esta eficiencia es absolutamente esencial para los patrones comunes de aplicación ZK soportados por Achronyme, como hashear eficientemente compromisos de votantes privados en un árbol de Merkle o generar anuladores para prevenir criptográficamente la doble votación.
Perspectivas Arquitectónicas Clave y Conclusiones
La transición de la ingeniería de compiladores tradicional a la compilación de circuitos de conocimiento cero requiere un cambio de paradigma fundamental. Basándose en el análisis arquitectónico profundo del pipeline de Achronyme, emergen varias perspectivas críticas que desafían las suposiciones estándar del desarrollo de software moderno:
- El Flujo de Control Dinámico es una Ilusión Temporal: En modo circuito, la ejecución es un mapeo espacial de relaciones, no una secuencia temporal de eventos. Dado que las restricciones de conocimiento cero deben abarcar simultáneamente todas las posibilidades lógicas para enmascarar qué ruta de ejecución específica fue tomada por el demostrador, ambas ramas de un condicional deben evaluarse completamente en el circuito físico. En consecuencia, el costo computacional se determina estrictamente por el tamaño total del código, no solo por la ruta ejecutada en tiempo de ejecución.
- Las Operaciones Lineales son Gratuitas; las Multiplicaciones son el Cuello de Botella (en R1CS): La notación Big O tradicional trata la adición y la multiplicación como operaciones de peso relativamente similar. En la aritmetización R1CS, un árbol de adición que suma mil variables cuesta exactamente cero restricciones porque colapsa completamente en una única combinación lineal. La multiplicación es la única métrica de costo de restricciones, forzando a los compiladores a optimizar agresivamente para minimizar las intersecciones no lineales.
- La Lógica Sub-Restringida es la Nueva Fuga de Memoria: En el desarrollo de aplicaciones estándar, las variables no utilizadas o validaciones omitidas típicamente conducen a errores lógicos menores o inflación de memoria. En circuitos ZK, crean vectores de ataque criptográficos fatales. La integración rigurosa del Análisis de Contaminación en Achronyme para rastrear entradas privadas no es simplemente un linter útil —es una puerta de seguridad indispensable que previene matemáticamente que demostradores maliciosos falsifiquen trazas de ejecución.
- Los Phi-Nodes son Obsoletos ante la Interpolación Algebraica: La ausencia total de ramificación dinámica hace obsoletas las fronteras de dominancia SSA estándar. El -node tradicional se reemplaza por instrucciones Mux explícitas y matemáticamente restringidas (por ejemplo, ) que interpolan el resultado correcto nativamente sobre el campo finito, simplificando la Representación Intermedia en un bloque perfectamente lineal.
- La Lógica a Nivel de Bits Exige Aritmetización Extrema: Las operaciones que son triviales y ultrarrápidas en una CPU de silicio (como < o XOR) son devastadoramente costosas en circuitos algebraicos. Esta restricción fuerza la adopción de alternativas matemáticas completamente diferentes y nativas para ZK, alterando fundamentalmente los bloques constructivos primitivos que los desarrolladores deben usar —como priorizar hashes Poseidon algebraicos sobre funciones SHA-256 estándar basadas en operaciones a nivel de bits.
- La Aritmetización Plonkish Ofrece una Vía de Escape mediante Lookups: Mientras que R1CS ofrece un procesamiento elegante de combinaciones lineales, la aritmetización Plonkish desplaza la carga de las operaciones complejas de la aritmética pura a búsquedas basadas en memoria. Al pre-computar combinaciones válidas en tablas estáticas, el backend Plonkish permite a los compiladores eludir la descomposición en bits por completo para operaciones pesadas específicas, destacando por qué los compiladores ZK modernos deben soportar múltiples backends objetivo para optimizar cargas de trabajo variadas.
- Emulación de Hardware mediante Representación de Montgomery: Dado que las CPUs estándar no pueden procesar nativamente aritmética de módulo primo de 254 bits de manera eficiente, el compilador mismo debe emular este hardware mediante representaciones por software. Al mapear la aritmética de campo al espacio de Montgomery utilizando limbs de 4x64 bits, Achronyme evita la degradación catastrófica de rendimiento durante las fases de compilación y generación de testigos.
El compilador de Achronyme representa una intersección fascinante entre la teoría clásica de lenguajes de programación y la criptografía moderna avanzada. Al eliminar los componentes dinámicos de la arquitectura von Neumann y optimizar rigurosamente la lógica estática restante para aritmética de campos finitos, automatiza exitosamente la traducción de lógica legible por humanos a las realidades matemáticas intransigentes requeridas por las pruebas de conocimiento cero.