Zero-knowledge proofs (ZKPs) represent a revolutionary advance in computational integrity, enabling one party to prove the correct execution of a computation without revealing the underlying private inputs. Historically, the engineering overhead required to construct these proofs has been immense. Developers were forced to write the general-purpose logic of their applications in traditional languages while implementing the cryptographic validation logic in highly specialized, low-level circuit languages. This bifurcation inevitably leads to duplicated effort, logic mismatches, and severe security vulnerabilities.
The Achronyme programming language was designed to resolve this fundamental impedance mismatch. By utilizing a dual-execution environment, Achronyme allows developers to write zero-knowledge programs using a single, unified syntax. The compiler takes a unified Abstract Syntax Tree (AST) and routes it toward two entirely different execution models: a standard, general-purpose Virtual Machine (VM) for dynamic execution, and a highly specialized arithmetic constraint compiler for zero-knowledge proof generation.
This research report provides an exhaustive technical analysis of the Achronyme zero-knowledge compilation pipeline. Focusing specifically on the ach circuit path, the analysis deconstructs how high-level programmatic constructs are systematically lowered into intermediate representations, rigorously optimized for finite field arithmetic, and ultimately translated into either Rank-1 Constraint Systems (R1CS) or Plonkish arithmetizations. By examining the source code logic (spanning from the entry points to the low-level BN254 field element implementation), this report bridges the conceptual gap between traditional compiler design and the strict mathematical realities of cryptographic circuits.
The Two Paths: Architectural Divergence from a Single AST
The architecture of the Achronyme compiler is defined by a strict bifurcation that occurs immediately after the parsing phase. The process begins in the achronyme-parser module, where a hand-written Pratt lexer and a recursive descent parser analyze the .ach source code to produce a standard Abstract Syntax Tree (AST). At this juncture, the orchestration logic determines the compilation trajectory based on the invoked command-line interface (CLI) arguments: ach run or ach circuit.
The AST diverges post-parsing into two vastly different computational paradigms. The primary path, invoked via ach run, directs the AST to a bytecode compiler that feeds a custom, von Neumann-style virtual machine. This VM path handles dynamic execution and provides a feature-rich environment complete with garbage collection (GC), dynamic memory allocation, support for complex closures, recursive function calls, and native input/output (I/O) operations. It operates sequentially, executing instructions and mutating state over time, mirroring the behavior of standard interpreters like the Java Virtual Machine or V8.
Conversely, the secondary path, invoked via ach circuit, enforces static unrolling and translation into polynomial constraints over finite fields. The circuit compilation path strips away the illusion of time and dynamic memory, forcing the program into a static, mathematical representation. In cryptography, a non-interactive zero-knowledge proof (such as a zk-SNARK) requires the prover to demonstrate knowledge of a “witness” (a vector of values) that satisfies a highly specific, fixed-size system of polynomial equations. Because arithmetic circuits are static graphs of mathematical relationships, they possess no program counter, no stack, and no mutable memory.
Consequently, the ach circuit compilation path imposes rigorous restrictions on the source AST that are enforced at compile time:
- Elimination of Dynamic Control Flow: While the AST may contain if/else conditionals, these cannot be executed dynamically. Hardware circuits cannot “jump” over instructions based on runtime data. The circuit must physically contain the evaluation logic for both the if branch and the else branch, multiplexing the final result based on the boolean condition evaluated as a mathematical formula.
- Prohibition of Unbounded Loops: Constructs such as while loops, or for loops where the bounding conditions are determined at runtime, are explicitly rejected. Furthermore, control flow interruptions like break and continue cannot be utilized in circuit mode. To translate a loop into a static equation, the exact number of iterations must be known at compile time so the loop body can be statically unrolled into a flat, linear sequence of operations.
- Strict Immutability and Absence of I/O: There is no concept of dynamic network requests, disk reads, or memory mutation during circuit evaluation. The concept of state mutation is an abstraction that the compiler must eliminate. This is achieved through the generation of a Static Single Assignment (SSA) Intermediate Representation (IR), where variables are mathematically immutable once assigned.
These restrictions are not arbitrary design choices; they are absolute mathematical prerequisites dictated by the arithmetization process of protocols like Groth16 or PlonK. A polynomial constraint system cannot feature an unknown number of terms (which a dynamic loop would generate) and cannot conditionally omit variables without destroying its algebraic properties. The compiler’s fundamental mandate is to flatten the multi-dimensional, temporal structure of a software program into a one-dimensional, static mathematical statement.
AST to SSA IR: The Lowering Phase
The transformation from the high-level AST to the Intermediate Representation (IR) is orchestrated within the IR types, lowering, and expression modules. Achronyme utilizes a Static Single Assignment (SSA) form. In standard SSA, every variable is assigned exactly once, and every variable is defined before it is used. This architecture perfectly mirrors the mathematical nature of zero-knowledge constraints: an equality constraint is not an imperative assignment that can be updated in a subsequent clock cycle; it is a permanent, immutable statement of truth for that specific witness configuration.
The Architectural Rejection of Phi-Nodes
The most striking architectural deviation in Achronyme’s SSA implementation, particularly when compared to traditional industrial compilers like LLVM or GCC, is the complete and intentional absence of -nodes (phi-nodes).
In traditional SSA form, a -node is a special instruction used to merge variables that have been assigned in divergent, mutually exclusive control flow paths. If a program contains an if/else block where a variable x is assigned the value a in the true branch and b in the false branch, the subsequent basic block in the Control Flow Graph (CFG) will begin with a statement such as x_3 = phi(x_1, x_2). The -function dynamically selects the value of x_1 or x_2 depending on which basic block was executed immediately prior to reaching the merge point.
In a zero-knowledge circuit, dynamic control flow does not exist. The circuit is a static mathematical formula evaluated simultaneously. The prover provides a complete witness, and the verifier checks the arithmetic relationships between all values in that witness. A polynomial equation cannot selectively ignore terms based on the evaluation of other terms without destroying its algebraic soundness.
Therefore, Achronyme’s lowering phase explicitly avoids -nodes and their associated complexities, such as computing dominance frontiers or dominator trees (e.g., the Lengauer-Tarjan algorithm). Instead, it flattens control flow using a mathematical multiplexer construct, represented internally as a Mux instruction. When the compiler encounters an if/else expression, it recursively evaluates both the if AST block and the else AST block, regardless of the condition. It then emits a Mux instruction that mathematically selects the correct value using algebraic interpolation:
Because the variable is rigorously constrained to be a boolean value ( or ), this equation neatly selects when the condition is true () and when the condition is false ().
Consider the concrete compilation of a conditional assignment: let r = if condition { a } else { b };.
The Achronyme compiler lowers this high-level AST node directly into the following flat SSA IR sequence:
| IR Instruction ID | Operation | Arguments | Mathematical Equivalent |
|---|---|---|---|
| v0 | Load | condition | Load boolean |
| v1 | Load | a | Load value |
| v2 | Load | b | Load value |
| v3 | Sub | 1, v0 | Compute |
| v4 | Mul | v0, v1 | Compute |
| v5 | Mul | v3, v2 | Compute |
| v6 | Add | v4, v5 | Compute |
| r | Store | v6 | Assign to output |
This design decision profoundly simplifies the data flow analysis downstream. Because there are no distinct basic blocks connected by conditional branching logic, the Control Flow Graph is entirely linear. The compiler does not need to resolve lost-copy problems or swap problems associated with -node destruction during back-end code generation. The entire circuit represents a single, monolithic basic block, mapping perfectly to a constraint system.
Static Loop Unrolling and Function Inlining
Similarly, the handling of loops and function calls, is dictated by the static nature of the target cryptographic backends.
A traditional loop mechanism relies on a backward jump in the instruction pointer (e.g., a JMP instruction in assembly) until a specific condition evaluates to false. Because an arithmetic circuit lacks an instruction pointer or the concept of temporal repetition, all iterations of a loop must exist as distinct, sequential mathematical constraints. When the compiler encounters a construct such as for i in 0..3 { sum = sum + arr[i]; }, it evaluates the bounds statically. If the bounds are dynamic and cannot be resolved at compile time, the compiler halts and emits a hard error.
If the bounds are statically known, the compiler performs mandatory, exhaustive loop unrolling. It duplicates the AST of the loop body for each iteration, substituting the loop index variable with the concrete integer value for that specific pass.
The original AST representation:
for i in 0..3 { sum = sum + arr[i]; }
Is lowered into the SSA IR as if the developer had explicitly written the sequential logic:
| Loop Iteration | Simulated SSA IR Emission |
|---|---|
| i = 0 | v_sum_1 = Add(v_sum_0, arr) |
| i = 1 | v_sum_2 = Add(v_sum_1, arr) |
| i = 2 | v_sum_3 = Add(v_sum_2, arr) |
Function calls are treated with an identical philosophy. There is no call stack, no frame pointer, and no dynamic dispatch in an arithmetic circuit. Every function call is completely and unconditionally inlined. The compiler maps the arguments to the function’s parameters, processes the function’s AST into a sequence of SSA instructions, and splices those instructions directly into the monolithic IR sequence. While this approach guarantees that the resulting circuit represents the exact mathematical constraints of the program, it introduces a trade-off: the compilation output size (and consequently, the proving time) grows linearly with the number of loop iterations and function invocations.
Optimization Passes: Minimizing the Constraint Footprint
In traditional compilation, optimization passes primarily target runtime CPU cycles, cache locality, and memory footprint. In the zero-knowledge paradigm, the size of the resulting constraint system dictates the performance of the cryptographic prover. Proving time is consistently the largest bottleneck in ZK systems, scaling quasi-linearly with the number of constraints (e.g., for operations involving Fast Fourier Transforms in algorithms like Groth16). Consequently, compiler optimization is not merely a tool for generating faster binaries; it is a critical, uncompromising requirement for making cryptographic proofs computationally feasible.
Achronyme implements four specific optimization passes over the flattened SSA IR, defined in the optimization passes module. While their names mirror standard compiler passes, their underlying rationales and mechanics are uniquely tailored to finite field arithmetic and ZK security paradigms.
1. Constant Folding: Constraint Eradication
In a standard compiler, constant folding evaluates deterministic expressions at compile time (e.g., replacing 5 * 8 with 40) to save a few CPU cycles at runtime. In Achronyme, constant folding eliminates cryptographic constraints entirely. If the compiler encounters let x = 5 * 8;, it evaluates this natively to 40 and replaces all usages of x with the literal field element 40. Because these values are completely deterministic, they do not need to be assigned to private witness wires in the circuit. Instead, constants are embedded directly into the constraint matrices as public, fixed coefficients. This optimization reduces the dimension of the witness vector and eliminates the multiplication gate that would have been required to mathematically prove .
2. Dead Code Elimination (DCE): Pruning the Graph
Dead Code Elimination removes unused instructions from the IR. Because the Achronyme circuit IR is perfectly linear and devoid of branches or -nodes, DCE is implemented as a highly efficient, reverse-order data flow graph traversal. Any SSA variable that is never read by a subsequent instruction, and does not represent a required public output or a hard assertion, is pruned from the IR. This pass is vital for preventing the generation of “orphan” constraints that burden the prover with computing and committing to values that do not contribute to the final truth of the statement being proven.
3. Boolean Propagation: Specialized Algebraic Optimization
Boolean propagation is a highly specialized optimization unique to algebraic and constraint-based compilation. In ZK circuits, all variables are fundamentally field elements, meaning they can take any integer value up to a massive prime . To enforce that a variable behaves strictly like a binary boolean (restricted to or ), the circuit must inject a quadratic constraint: .
This polynomial equation only holds true if or . However, these boolean constraints are mathematically expensive. If a developer uses a boolean value in multiple places, a naive compiler might emit the constraint repeatedly. Furthermore, if is the output of a logical comparison (which inherently outputs or based on its internal gadgetry), the boolean nature of the variable is already guaranteed by the preceding logic.
Achronyme’s Boolean Propagation pass utilizes bound propagation techniques (similar to those used in Integer Linear Programming (ILP) and SAT solvers) to track the “proven boolean” status of every variable in the SSA graph. The compiler maintains a specialized set of SSA IDs that have been mathematically constrained to the bounds . When an instruction requires a boolean input (such as the condition variable in a Mux multiplexer), the compiler checks this set. If the variable is already classified as a proven boolean, the compiler safely skips the generation of the redundant enforcement constraint, saving one multiplication gate per skip.
4. Taint Analysis: Securing the Circuit’s Integrity
Of all the optimization passes, Taint Analysis is the most crucial for the fundamental cryptographic security of the application. In traditional software engineering, an unused input or an under-constrained variable might result in a minor logical bug or wasted memory. In a zero-knowledge circuit, an under-constrained variable represents a catastrophic, systemic vulnerability.
A zero-knowledge proof verifies only the mathematical constraints explicitly encoded within the circuit. If a developer declares a private witness variable representing a secret_key, but fails to include an assertion that verifies a cryptographic signature against that key, the variable is effectively unconstrained. A malicious prover could supply any arbitrary value for secret_key, generate a perfectly valid mathematical proof, and completely bypass the intended authentication logic.
Achronyme leverages static taint analysis (borrowing concepts from information flow analysis tools like FlowDroid) to detect these vulnerabilities at compile time. The compiler treats all private witness inputs as “tainted” sources. It traces the data flow graph forward to ensure that every tainted variable eventually flows into a verified sink: a hard assertion, a public output, or a constrained cryptographic primitive (such as a hash function). If a witness variable reaches the end of the data flow graph without affecting any constrained output, the compiler issues a severe warning that the circuit is under-constrained. This proactive, compile-time safety check prevents critical vulnerabilities before a single proof is ever generated.
IR → R1CS: The Rank-1 Constraint System
After the optimization passes reduce the SSA IR to its minimal necessary form, the compiler must translate these abstract instructions into the native mathematical format of the chosen cryptographic backend. For the Groth16 prover, this target format is the Rank-1 Constraint System (R1CS), managed in the R1CS backend and constraints modules.
R1CS is an arithmetization scheme where an entire computation is represented globally as a set of three matrices , and , alongside a single witness vector . The system is mathematically satisfied if, and only if, the following equation holds true:
Here, denotes the Hadamard product, representing element-wise multiplication of the resulting vectors. This rigid structure implies that each row in the matrix system represents exactly one multiplication of two linear combinations. The elegance (and the fundamental computational limitation) of R1CS is that it natively supports unlimited addition and scalar multiplication for free, but strictly limits the circuit to exactly one multiplication of distinct variables per constraint row.
The Strict Wire Layout Invariant
To facilitate this matrix algebra, the witness vector (often referred to as the wire layout) must adhere to a highly specific ordering invariant. In Achronyme, the wire layout is strictly ordered as:
[ONE, ...public_inputs, ...private_witnesses]
Why ONE? The constant must always be the first element (index 0) of the witness vector. Because R1CS logic relies purely on linear combinations of variables, there is no inherent mechanism to add a bare constant to a variable without multiplying it by a known value already present in the vector. If an operation requires adding the constant 5 to a variable , the linear combination must be expressed mathematically as . By permanently fixing the 0th index of the witness vector to the constant field element , constants can be seamlessly and infinitely integrated into the , and matrices.
Why Public preceding Private? The public inputs must precede the private witness data because of the operational mechanics of pairing-based verification protocols. During the proof verification phase, the verifier (which may be a smart contract on a blockchain) must construct a subset of the polynomial equation using only the publicly known data. By grouping all public inputs at the beginning of the vector, the cryptographic protocol can cleanly slice the vector into a public segment (processed cheaply by the verifier) and a private segment (processed solely by the prover during proof generation).
Tracing a Concrete Arithmetic Circuit
Consider the compilation of a simple arithmetic circuit statement representing the core equation :
pub x; witness y; assert_eq(x * y + 1, 42);
The optimized SSA IR provides a single instruction to enforce this relationship. The compiler must map this into the format. The mathematical equality is , which algebraically rearranges to a pure multiplication constraint:
The wire vector is initialized by the compiler as [ ONE, x, y ] (where the constant ONE is at index 0, is the public input at index 1, and is the private witness at index 2).
To encode the constraint , the Achronyme compiler generates a single row in the constraint matrices:
- Vector must extract : [ 0, 1, 0 ]
- Vector must extract : [ 0, 0, 1 ]
- Vector must extract the constant : [ 41, 0, 0 ]
When taking the dot product with the wire vector :
The Hadamard product ensures . This perfectly enforces the logic using exactly one R1CS constraint.
Non-Native Gadgets and Bit Decomposition
A critical design challenge arises when an expression does not naturally fit the quadratic form. R1CS does not possess native CPU instructions like division (/), modulo (%), or bitwise comparisons (>, <). The compiler must replace these high-level operations with “gadgets”: complex sub-circuits of constraints that algebraically enforce the exact same logic.
For example, a division operation cannot be evaluated directly because finite fields do not support floating-point division or standard integer division. The compiler rewrites this as a multiplication constraint: . The prover is responsible for computing the modular inverse of natively during execution to find , but the circuit only proves that the inverse multiplication holds true.
Comparisons, such as , are incredibly expensive in R1CS. Because field elements exist in a modular arithmetic space without intrinsic ordering beyond their bit representation, comparing two numbers requires full bit-decomposition. The compiler must extract the binary representation of the variables, constrain each individual bit to be boolean (), and then perform a bitwise subtraction to check for mathematical underflow. A single less-than comparison in the BN254 field generates approximately 254 distinct constraints. This extreme disparity in cost, where a multiplication costs 1 constraint and a simple comparison costs 254, highlights precisely why specialized compilation strategies for ZK are strictly required.
IR → Plonkish: The Alternative Backend
While R1CS is elegant and ideal for generating proofs via the Groth16 protocol, it possesses notable limitations regarding memory usage, the requirement for circuit-specific trusted setups, and its inability to naturally handle complex custom logic. Achronyme mitigates these limitations by providing a secondary, highly optimized compilation path to the “Plonkish” arithmetization scheme, utilized by the KZG-PlonK prover, managed in the Plonkish backend module.
Plonkish arithmetization represents constraints not as independent, isolated matrices, but as a continuous rectangular matrix (or grid) of values, often referred to as an execution trace. Instead of relying on the format, Plonkish relies on a fundamental custom gate equation, governed by a series of “selector polynomials”:
In this architecture, and represent the physical wire values (left input, right input, and output), while the variables () are fixed selector constants defined by the compiler to dictate the behavior of the gate for that specific row.
To perform a standard addition, the compiler simply disables the multiplication selector by setting , reducing the equation to . To perform a multiplication, it activates and appropriately adjusts the addition selectors.
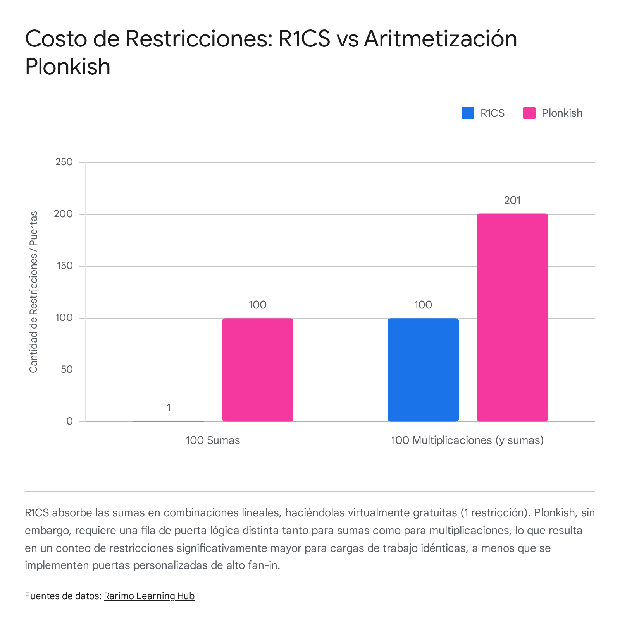
Structural Divergence and Advanced Plonkish Features
The structural difference between the backends forces the Achronyme compiler to utilize drastically different layout strategies depending on the chosen arithmetization.
In R1CS, an addition tree comprising hundreds of variables (e.g., ) is absolutely free because all terms can be rolled into a single linear combination within a single matrix vector. In Plonkish, however, the standard gate equation natively accepts only three variables (). Therefore, a large addition tree must be broken down into multiple sequential gates, consuming substantially more rows and increasing the proving time for linear operations.
However, Plonkish compensates for this limitation with two massive structural advantages: Copy Constraints and Lookup Arguments.
Because variables in Plonkish are placed in a highly structured grid, the compiler can enforce mathematical equality between variables used in entirely different parts of the circuit via a permutation argument, commonly referred to as copy constraints. If a variable x is computed in row 5 and required again in row 500, the compiler does not need to re-verify its algebraic lineage or spend constraints moving it. It simply asserts that the cell at (row 5, column a) is mathematically identical to the cell at (row 500, column b). This global routing capability significantly reduces the overhead of tracking variable states across complex logic paths.
Furthermore, Plonkish allows the Achronyme compiler to utilize Lookup Arguments (often implemented as PLOOKUP). For operations that are highly inefficient to compute algebraically (such as bitwise XOR, AND, or range checks), the compiler can precompute a massive, static table of all valid input and output combinations. Instead of decomposing variables into 254 individual binary constraints to perform a single XOR operation, the Plonkish backend simply outputs a constraint asserting that the tuple exists somewhere within the precomputed lookup table. This mechanism effectively collapses thousands of complex mathematical constraints into a single, efficient table lookup, dramatically accelerating the processing of standard cryptographic primitives and bitwise arithmetic.
Field Arithmetic: The Mathematical Foundation
Regardless of the selected compilation target (R1CS or Plonkish), all arithmetic within Achronyme is strictly and universally defined over the BN254 scalar field. This is a specific finite field characterized by a prime order (specifically 21888242871839275222246405745257275088548364400416034343698204186575808495617).
The decision to hardcode BN254 is entirely pragmatic. BN254 is heavily entrenched in the blockchain ecosystem due to its native support via precompiles on the Ethereum Virtual Machine (EVM). By targeting this specific field, Achronyme ensures that the generated .r1cs and .wtns files can be directly exported to tools like snarkjs to generate Solidity verifier contracts, allowing proofs to be verified natively on-chain. Consequently, every variable, boolean flag, memory address, and array index in Achronyme is fundamentally processed as a 254-bit scalar field element.
Because the host hardware running the compiler and prover (usually a standard x86 or ARM CPU) operates natively on 64-bit registers, computing modular arithmetic over a 254-bit prime is computationally taxing. Standard modulo operations (division) are among the most expensive instructions in a modern CPU pipeline. To circumvent this hardware limitation, the Achronyme compiler implements Montgomery representation for all internal field element calculations.
Montgomery arithmetic transforms the variables from their standard form into a scaled form , where is a highly optimized power of 2 (typically to align perfectly with the four 64-bit limbs used to store the 254-bit integer).
The brilliance of the Montgomery form is evident during field multiplication. Instead of executing the standard computation , which requires an expensive multi-precision division to find the remainder, the runtime computes the Montgomery multiplication:
Because is a power of 2, multiplying by its inverse effectively reduces the complex division into a series of binary shifts and bitwise masking operations, which are heavily hardware-accelerated on modern processors. By mapping the AST’s field arithmetic directly into Montgomery space using 4x64-bit limbs, Achronyme achieves the high-performance, in-process native proving necessary to generate complex zero-knowledge proofs rapidly, entirely bypassing the need to rely on slower external JavaScript or Python tooling.
Poseidon: A ZK-Native Hash Function
Traditional software engineering relies heavily on standardized cryptographic hashes like SHA-256 or Keccak-256 for data integrity and commitments. However, attempting to integrate these standard algorithms into a zero-knowledge circuit exposes the fundamental mismatch between CPU architectures and finite field constraints.
SHA-256 was explicitly designed to be fast on hardware CPUs. It operates heavily on 32-bit words using rapid bitwise operations such as AND, XOR, and bitwise shifts (SHR). As established previously, bitwise operations in algebraic constraint systems require completely decomposing variables into individual bits, costing hundreds of constraints per operation. Evaluating a single SHA-256 hash in R1CS consumes approximately 25,000 to 30,000 constraints. In a system where proving time and memory usage scale directly with constraint counts, relying on SHA-256 makes large-scale data verification computationally intractable.
To solve this severe bottleneck, Achronyme’s constraint system natively integrates the Poseidon hash algorithm, with its implementation details housed in the Plonkish constraints module. Poseidon is a “ZK-native” algebraic hash function designed from the ground up to minimize constraints over prime fields like BN254.
Instead of relying on bitwise manipulation, Poseidon operates via full and partial algebraic rounds utilizing the Hades sponge construction. A typical round consists of adding round constants (a free linear operation in R1CS), multiplying the state by a Maximum Distance Separable (MDS) matrix (which requires only linear combinations, also practically free in R1CS), and passing the state through a non-linear S-box.
Crucially, the S-box in Poseidon is not a complex byte-lookup table like those used in AES, but rather a simple, low-degree polynomial exponentiation. Over the BN254 field, Poseidon specifically uses , meaning the S-box maps the state element to .
Because can be computed algebraically through simple successive multiplication:
- Compute
- Compute
- Compute
The entire non-linear S-box operation requires only 3 field multiplications, and thus exactly 3 R1CS constraints. This profound mathematical optimization allows Achronyme to constrain an entire Poseidon hash computation using only ~200 to 300 total constraints, making it roughly 100 times more efficient than a comparable SHA-256 circuit. This efficiency is absolutely essential for the common ZK application patterns supported by Achronyme, such as efficiently hashing private voter commitments into a Merkle tree or generating nullifiers to cryptographically prevent double-voting.
Key Architectural Insights and Takeaways
Transitioning from traditional compiler engineering to zero-knowledge circuit compilation requires a fundamental paradigm shift. Based on the deep architectural analysis of the Achronyme pipeline, several critical insights emerge that challenge the standard assumptions of modern software development:
- Dynamic Control Flow is a Temporal Illusion: In circuit mode, execution is a spatial mapping of relationships, not a temporal sequence of events. Because zero-knowledge constraints must simultaneously encompass all logical possibilities to mask which specific execution path was taken by the prover, both branches of a conditional must be fully evaluated in the physical circuit. Consequently, the computational cost is determined strictly by the total size of the codebase, not just the path executed at runtime.
- Linear Operations are Free; Multiplications are the Bottleneck (in R1CS): Traditional Big O notation treats addition and multiplication as operations of relatively similar weight. In R1CS arithmetization, an addition tree summing a thousand variables costs exactly zero constraints because it collapses entirely into a single linear combination. Multiplication is the sole metric of constraint cost, forcing compilers to optimize aggressively to minimize non-linear intersections.
- Under-Constrained Logic is the New Memory Leak: In standard application development, unused variables or missed validations typically lead to minor logic bugs or memory bloat. In ZK circuits, they create fatal cryptographic attack vectors. Achronyme’s integration of rigorous Taint Analysis to track private inputs is not merely a helpful linter; it is an indispensable security gate that mathematically prevents malicious provers from faking execution traces.
- Phi-Nodes Are Obsoleted by Algebraic Interpolation: The complete lack of dynamic branching renders standard SSA dominance frontiers obsolete. The traditional -node is replaced by explicit, mathematically constrained Mux instructions (e.g., ) that interpolate the correct result natively over the finite field, simplifying the Intermediate Representation into a perfectly linear block.
- Bitwise Logic Demands Extreme Arithmetization: Operations that are trivial and ultra-fast on a silicon CPU (like < or XOR) are devastatingly expensive in algebraic circuits. This constraint forces the adoption of entirely different, ZK-native mathematical alternatives, fundamentally altering the primitive building blocks developers must use, such as prioritizing algebraic Poseidon hashes over standard bitwise SHA-256 functions.
- Plonkish Arithmetization Offers an Escape Hatch via Lookups: While R1CS offers elegant processing of linear combinations, Plonkish arithmetization shifts the burden of complex operations from pure arithmetic to memory-based lookups. By precomputing valid combinations into static tables, the Plonkish backend allows compilers to bypass bit-decomposition entirely for specific heavy operations, highlighting why modern ZK compilers must support multiple backend targets to optimize varied workloads.
- Hardware Emulation via Montgomery Representation: Because standard CPUs cannot natively process 254-bit prime modulus arithmetic efficiently, the compiler itself must emulate this hardware via software representations. By mapping field arithmetic into Montgomery space utilizing 4x64-bit limbs, Achronyme avoids catastrophic performance degradation during the compilation and witness generation phases.
The Achronyme compiler represents a fascinating intersection of classic programming language theory and advanced modern cryptography. By stripping away the dynamic components of the von Neumann architecture and rigorously optimizing the remaining static logic for finite field arithmetic, it successfully automates the translation of human-readable logic into the uncompromising mathematical realities required by zero-knowledge proofs.